IEEE COMPUTER ARCHITECTURE LETTERS, VOL. 24, NO. 1, JANUARY-JUNE 2025
Accelerating Page Migrations in Operating Systems With Intel DSA
Jongho Baik , Jonghyeon Kim , Chang Hyun Park , Member, IEEE, and Jeongseob Ahn
https://ieeexplore.ieee.org/document/10841986
- index terms - data migration, hardware accelerator, linux
해당 아티클은 구독자 대상으로 pdf가 공개되므로 블로그 게시글에서 원문은 포함하지 않을 예정
Modern server-class CPUs are introducing special-purpose accelerators on the same chip to improve the performance of data-intensive applications.
This paper proposes a method to accelerate data migrations within the operating system using Intel’s Data Streaming Accelerator (DSA).
To the best of our knowledge, this is the first study that exploits a hardware-assisted data migration scheme in the operating system.
Linux kernel components that can benefit from hardware acceleration.
>> kernel system using kernel function (migrate_pages())
hardware accelerator is not suitable for transferring a small amount of data due to the HW setup overhead
>> accelerating migrate_pages() with DSA (dynamically determines the offloading decision based on the volume of pages)
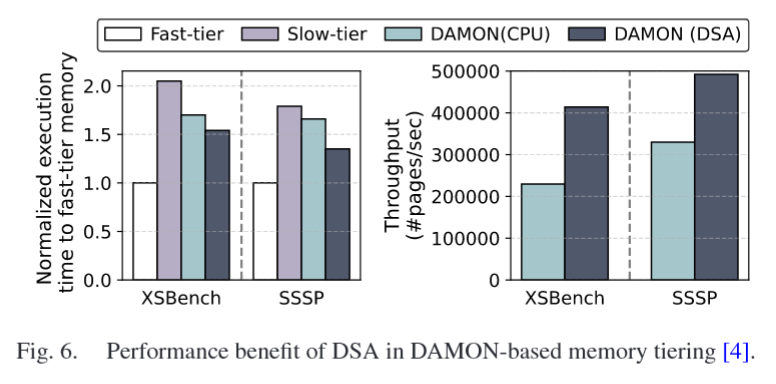
>> real-world page compaction (kcompactd) and promotion (kdamond) scenarios
kcompactd : rearrange physical pages → mitigate the memory fragmentation, larger contiguous free memory pages
DAMON's kdamond : kernel daemon thread ... that continuously runs in the background within the Linux kernel to perform specific tasks ... promote frequently accessed pages to faster memory, or demote infrequently accessed pages to slower memory
+) DAMON = Data Access MONitor ... monitoring memory access pattern
>> revised migration function processes a batch of pages that is more efficient for DSA and outperforms the CPU-based migration
--
heterogeneous memory (dram+nvm or fast+slow) / tiered memory (HBM, DDR, PMEM ...)
accelerating the migrate_pages() function is crucial for enhancing the efficiency and performance of the Linux kernel’s memory management system
some prior studies on accelerating data migrations in the os (related work)
Nimble page management for tiered memory systems : parallelization technique to achieve speedup for transferring pages between different types of memory
HeMem : DMA engine to offload the data migration
vector instructions : the parallel processing of multiple data in a single instruction but additional overhead of saving and restoring the AVX registers
--
intel dsa
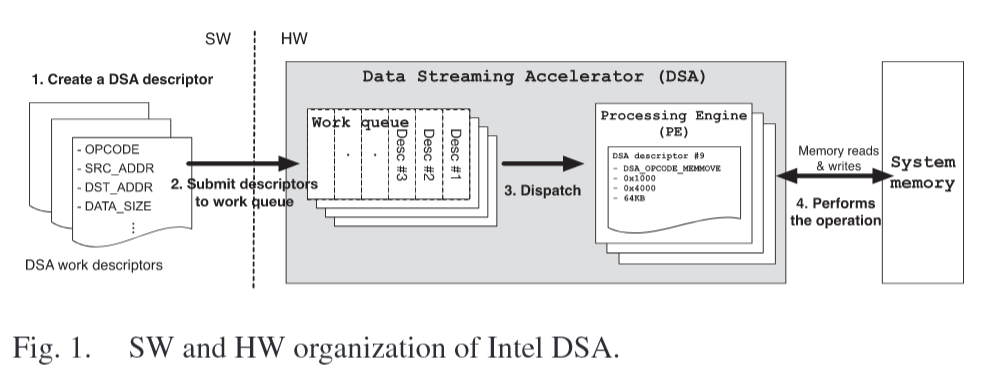
dsa hw unit includes work queues (WQs)
WQs hold DSA descriptors
Each descriptor specifies an operation type, src address, dest address, size
Intel DSA exposes portals
dev can submit the dsa descriptors using portal
MMIO = memory mapped io = hw dev register or control port - memory
... the execution unit inside the DSA that performs the actual operations.
portal = the entry in the MMIO address space used to submit DSA descriptor
... since it is a specialized hardware device that cannot be used like regular instructions, commands are issued by writing to memory-mapped addresses
pe = processing entry = executing the operation by fetching a descriptor from the work queue
---
migrating pages requires TLB shootdown operations
(when page table changes)
to reduce the migration overhead, Linux v6.3 added features to migrate pages in a batch through migrate_pages_batch(), which is also utilized in DAMON with a list of pages (folios)
the latest page management approach in the Linux kernel. A folio is an object that groups multiple pages (e.g., 2 or 4) into a larger unit.
DAMON tracks memory access patterns based on folios and processes them in batches during migration.
---
accelerating data migration with dsa
memcpy() function is the core primitive for copying data ... widely use!
... transferring data from the kernel to the user in a read() system call
... device drivers to copy data from the device-specific memory to the system memory
>> first-order consideration is to study and amortize the HW offloading cost !!
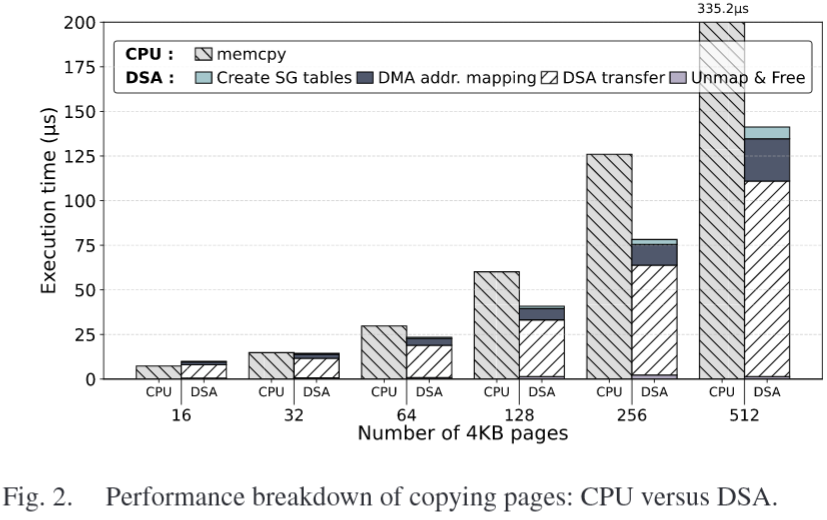
time for copying 4kb pages >> DSA is preferred when the number of pages exceeds 32
in the CPU configuration, we measured the time spent copying pages through copy_highpage() in /include/linux/highmem.h
if the amount of data is not sufficiently large, it is more efficient to use the conventional CPU copying method due to the offloading cost
costs are non-negligible when the amount of data to be moved is small
>> it is important to make an offloading decision based on the amount of data movement
offloading
- create SG table - dma mapping config - submit dsa descriptor - unmap
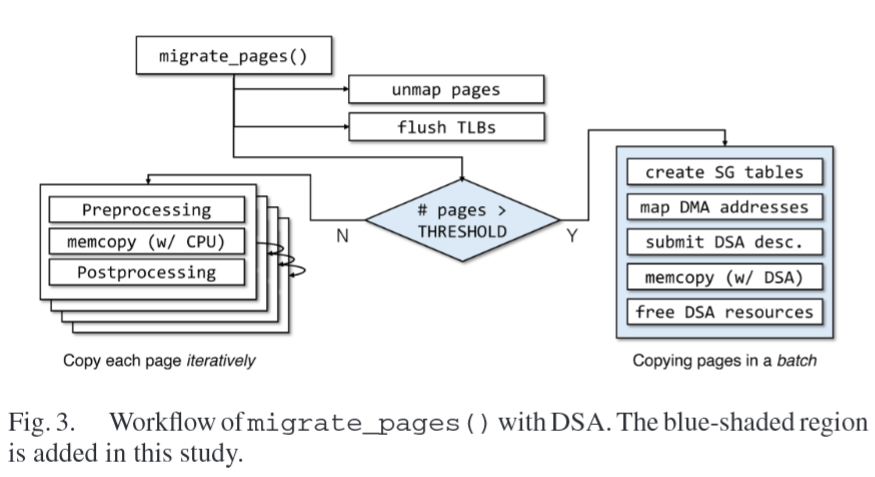
revised migrate_pages() function designed to exploit the performance advantages of DSA
an additional path (right-hand side of the figure) for migrating pages with DSA and the migration path with CPU remains as a fallback mechanism that is used when the number of pages is less than the threshold (e.g., 32)
DSA path to perform the migrations in a batch to minimize the offloading overhead
- build the scatter-gather tables for all the pages to be migrated and then generate DMA-capable addresses at once
- reserve a DSA engine for the operating system to exclusively use one work queue and one PE unit during boot time
- Once a DSA descriptor is submitted to the queue, the corresponding PE unit fetches an item and starts the data movement without the CPU’s involvement
- migrate_page operations were run synchronously, where the kernel thread waited for the completion of the transfer through busy waiting
- an asynchronous approach switching to other kernel tasks in future work
https://github.com/Sys-KU/DSA-Linux
---
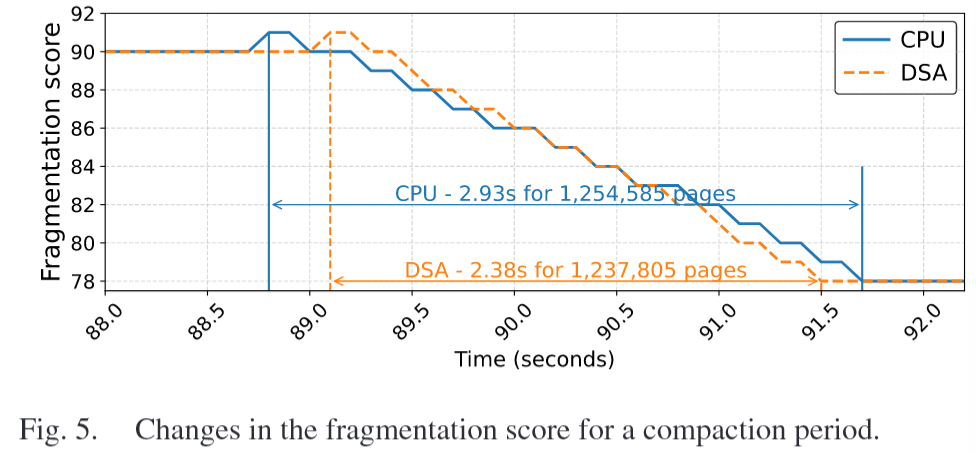
select two scenarios: memory compaction and memory promotion
- kcompactd
- how many pages are processed per second

- fragmentation score during a compaction period
- page promotion in tiered memory environments
decompose the migration time into the setup cost and actual data transfer
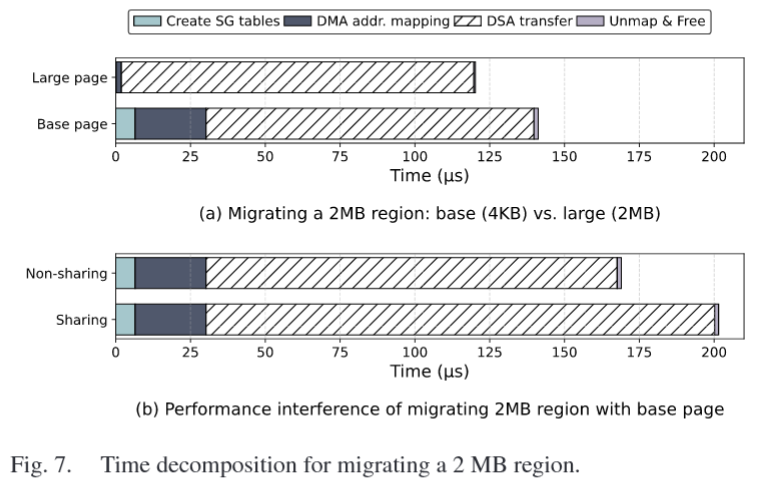
- the latency changes when a user application thread and a kernel thread utilize DSA at the same time