
정보 검색
- 대규모 정보 컬렉션에서 정보 요구 사항을 충족하는 비구조화된 자료를 찾는 것


1996 주로 텍스트 위주인 비정형 데이터의 양이 더 많았으나 효율적인 활용이 어려웠음
당시 기업들의 비즈니스 관련 시스템은 정형 데이터 기반이라 정형에 더 큰 가치를 둠
2006 웹 기반 정보가 대량 생성되면서 비정형 데이터 양도 늘었다
비정형 데이터의 시장 가치도 급상승. 검색 엔진 회사들이 비정형 데이터도 효율적으로 검색 활용할 수 있도록 했기 때문이다
비정형 데이터를 다루는 기술의 가진 그룹들의 등장과 임팩트
유닉스에서 파일에 등장하는 키워드를 찾기 위해 사용할 수 있는 것은 grep
grep 명령은 파일에서 패턴을 검색하고 일치하는 각 줄을 표준 출력에 기록
-v 옵션을 추가해서 중복 제외 가능

- 현재 디렉토리의 모든 파일에서 brutus가 포함된 줄 검색
- brutus가 포함된 줄을 찾은 후 그 중 ceasar가 포함된 줄 검색
- brutus와 ceasar는 포함하지만 calpurnia는 포함하지 않는 줄 검색
- ceasar가 포함되지 않는 줄 검색
grep 단점
- 큰 데이터셋에서 느리다 = 많은 문서에서 특정 패턴을 모두 검색해야하니
- 활용한 실행이 불가능하다 = not 연산처럼 활용 연산이 복잡하고 비효율적, 인접 단어 조회 읽기 요청도
- 순위 검색이 불가능하다 = 일치하는 라인을 반영하는 것일 뿐, 문서의 관련성이나 우선순위 반영은 없음
term-document incidence matrix 용어-문서 발생 행렬
행은 용어 , 열은 문서
해당 문서에 특정 단어가 포함되어있으면 1, 없으면 0
incidence vector 발생 벡터
용어마다 벡터를 가지고 있음
비트열이 저장되어 있고 각 비트가 포함여부를 의미
질의어를 처리할 때는 AND OR처럼 비트 연산으로 처리 가능
정보 검색 시스템의 기본적인 가정
- 컬렉션 : 검색 대상, 고정된 문서 집합
- 골 : 사용자 쿼리에 의거해 문서 검색하고 사용자에게 필요한 정보 제공
클래식한 검색 모델 형태
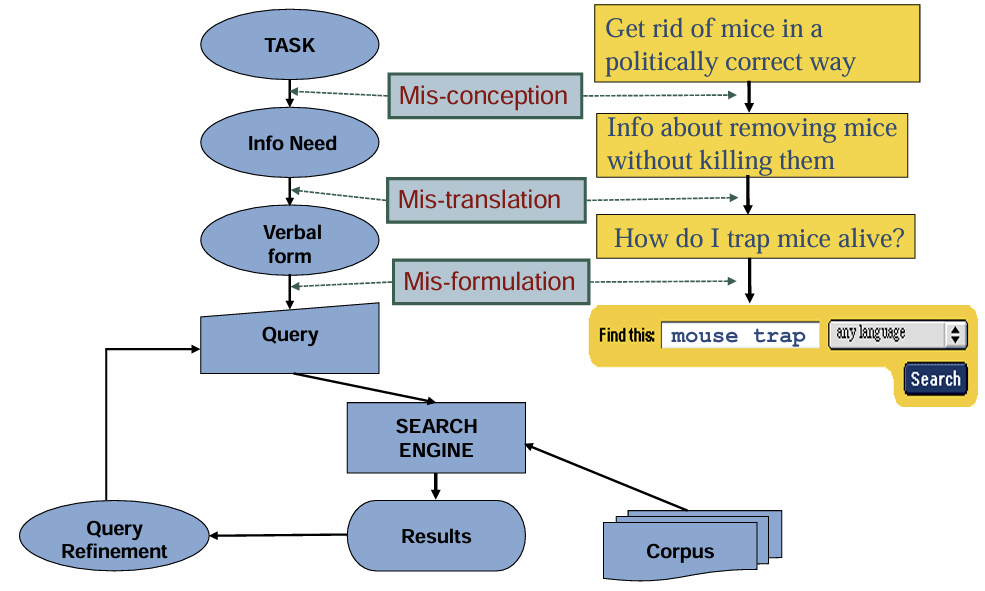
검색 결과 문서의 품질
- 정확도 = 사용자 쿼리와 관련된 검색 문서 비율
- 리콜 = 컬렉션에서의 관련 문서 비율
- f measure = 정밀도와 리콜 조화평균
더 큰 컬렉션, 더 큰 대규모 데이터 셋일 때
- 100만개의 문서를 포함하는 데이터셋에서
각 문서당 평균 1000개의 단어를 가지고 있고
단어는 평균 6바이트 정도라고 가정하면 문서는 총 6GB 정도이다
- 50만 개 정도의 고유 단어를 포함하고 있다고 할 때
그 고유어를 기준으로 term document matrix를 구축할 수 있고
각 단어가 각 문서마다 포함되었는지 여부를 1과 0으로 표현하면 다음과 같다

- 다만 문제점이 있다면 큰 데이터셋일수록 방대한 행렬이 되고
그림의 경우에서는 5천억개의 0과 1이 있다
- 대부분 0이고 가끔 1이 나타나는 sparse한 행렬
- 하지만 저장공간의 문제도 있고 탐색하기도 쉽지는 않다
inverted file , inverted index
postings list = 각각의 term을 포함하는 모든 문서의 docID를 목록으로 저장
배열보다는 연결리스트를 선호 > 동적 관리 유리, 단어 삽입 유리, 포인터 오버헤드 있
정렬은 docID 오름차순으로 > boolean 쿼리나 병합 연산에서 유리
inverted index construction
- tokenizer = 문서를 단어 단위로 분할 (토큰화)
- linguistic modules = 단어를 정규화해서 일관된 형태로
- indexer = 정규화된 단어가 포함된 문서의 id 기반
indexer steps
- (term, docID) 쌍으로 , term 순으로 정렬
- term frequency = 한 문서 내에서 특정 단어가 몇 번 등장했는지 카운트 > 중요도. 쿼리 처리나 문서 순위 결정에 사용
dictionary list and postings list
- inverted index 작업의 결과를 좌우 분할해서 좌측은 dic list 파일, 우축은 postings list 파일
dic 파일 > 메모리
postings list 파일 (단어를 포함하는 문서의 id) > 디스크
+ term frequency docu frequency 빈도 정보도 저장해서 각 문서나 단어의 중요성 포함
인메모리 postings 구현 구조
- 연결 리스트
- 가변 길이 배열
- 하이브리드 연속
boolean 쿼리를 처리하는 방식 > 단순한 쿼리지만 inverted index로 효율적 처리 가능
- 교집합 쿼리 conjunctive 두 단어 모두 포함 문서 검색
- 합집합 쿼리 disjunctive 두 단어 중 하나 이상 포함 문서 검색
쿼리 프로세싱 : and
- a and b
- a와 b 각각의 postings list를 찾기
- and 연산 수행을 위해 교집합 찾기
- 두 리스트를 각각 순차 탐색하며 동일한 문서 id를 발견하는 경우
결과 리스트에 그 id를 추가하는 방식으로 작동
(리스트 정렬이 필요했던 이유)
쿼리 최적화
- and 연산을 수행하는 경우 가장 효율적인(= 전체 처리 시간을 줄이기 위) 처리 순서를 결정해야함
- 각 단어에 대해 postings list 를 가져온 다음 문서 빈도 DF 가 낮은 리스트부터 처리하는 것이 효율적

- 문서 빈도가 낮은 순서로 리스트를 처리하고 가능한 일찍 교집합을 좁혀가야함
- 짧은 리스트부터 결합하면 중간 단계에서 연산을 줄여 최종 결과를 더 빠르게 얻을 수 있기 때문
- caesar의 postings list가 가장 짧으니
caesar와 brutus의 교집합을 먼저 계산하고 calpurnia와 결합
more general optimization
- (madding OR crowd) AND (ignoble OR strife) AND (killed OR slain) 처럼 복잡한 쿼리의 경우
or 조건은 각 단어의 빈도를 더해서 크기를 추정하고
가장 작은 or부터 처리하고
and 조건은 작은 크기부터 결합해서 효율적으로 연산한다
- (tangerine OR trees) AND (marmalade OR skies) AND (kaleidoscope OR eyes)
= (kaleidoscope OR eyes) AND (tangerine OR trees) AND (marmalade OR skies)
- and or 의 순서를 변경해도 결과는 동일하기 때문에 가능
beyond term search
용어 검색 이상의 정보 검색은 세 가지 종류
- 구 검색 phrase search - 단어들이 정확한 순서와 위치에 있는 구문 > 단어만 일치하는 것이 아니라 특정 의미를 갖는 특정한 구를 찾을 수 있어야 함
- 근접 검색 proximity search - 두 단어가 서로 가까이 있는 문서를 찾는 구문 > 위치 정보 저장 인덱스 필요
- 문서의 영역 검색 zonal search - 검색 기능처럼 문서 내에서 특정한 속성에 따라 필터링할 수 있어야 함
위치 정보를 포함한 inverted index

- 단어가 문서 내에서 등장하는 위치정보도 포함한 인덱스
- Brutus /3 Calpurnia /5 Caesar 라는 쿼리는
brutus와 calpunia가 3 단어 이내, calpurnia와 caesar가 5 단어 이내에 등장하는 문서를 찾아야 함
- 각 단어가 등장하는 위치 정보를 비교해서 근접도를 확인해야 하기 때문
Inverted index with term frequency = tf
- 검색어가 문서에서 몇번 나타나는지에 따라 관련성이 축적됨
- tf가 0과 1이면 전혀 없는 것과 있는 것은 차이가 있어야 하고
- 2와 1이거나 3과 2라면 등장 빈도에 따라 관련성 정도에 차이가 있다고 판단해야함

- dictionary list의 term과 연결된 postings list - term이 등장하는 모든 문서
- postings list에 저장된 docu ID마다 position information list (파란색) - 해당 문서에서 term이 등장하는 모든 위치
- postings list에 저장된 docu ID와 대응되는 term frequency (빨간색) - term이 문서에 등장하는 횟수
검색 결과 순위
- 부울 쿼리는 순서는 포함 또는 제외 ... 조건에 맞는지 아닌지만 판단하기 때문에 순서를 부여할 수 없음
- 순서를 부여할 때는 관련성이 높은 순서대로 정렬해야하기 때문에 관련성을 평가할 기준이 필요
> 근접성(가까운 위치에 있는 단어가 많을수록 높은 순위) , 용어의 빈도(자주 등장할수록 중요도 높음), reverse chronological order(= 역연대기적 정렬 =최신순정렬)
비구조화 데이터
- 비구조화 데이터는 주로 텍스트
- 데이터베이스보다 정보검색 시스템이 키워드 검색에 더 적합
반구조화 데이터
- 완전 비구조는 아니고 어느 정도의 구조를 일부 가지고 있음
- Title contains data AND Bullets contain search 처럼
특정 필드에 포함된 내용을 검색할 수 있는 기능이 필요함
반구조화 데이터 - xml
xml은 반구조화 데이터
<title>, <author>, <genre>, <publish_date> 같은 특정 태그에 기반해 데이터 검색
고급 반구조화 데이터 검색
Title is about Object Oriented Programming AND Author something like stro*rup
title 필드에서 object oriented programming 과 관련된 내용 검색하고
author 필드에서 stro*rup와 비슷한 이름을 검색
about울 처리하는 방법 > 특정 키워드만 포함하면 되는지 개념적인 설명을 포함하는 것인지
검색 순위 부여 > 관련성을 부여하는 랭킹 알고리즘
clustering and classification
- 클러스터링 군집화
문서의 내용을 바탕으로 유사한 문서들끼리 그룹으로 묶는 과정
- 클래시피케이션 분류
주어진 문서를 미리 정의된 주제(레이블)에 맞춰서 할당하는 작업
web
- 다양한 형식과 내용의 문서가 존재하는 웹
- 다양한 쿼리와 정보 요구 발생
- 텍스트 기반 정보만을 사용하는 것 뿐 아니라
링크 분석, 클릭스트림 분석 등 유저 행동을 이해하고 검색 품질 향상시키기
