1. dictionary data structure
사전에는 term , document frequency, postings list 를 저장하고 있음
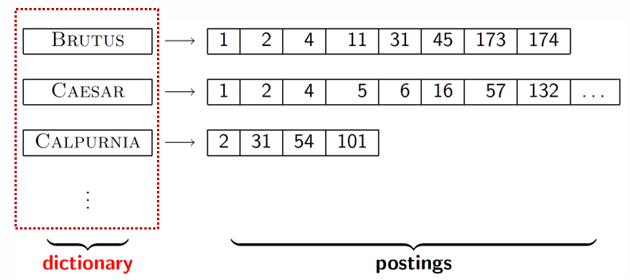
brutus 라는 단어는 1, 2, 4, 11, 31 등의 문서에서 나오고 단어가 등장하는 문서의 id는 postings list에 저장함
* a simple dictionary
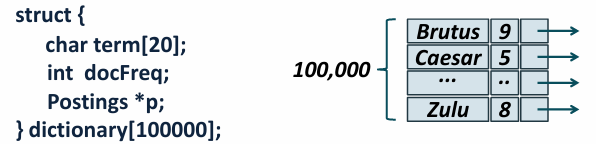
각 단어에 대해 구조체를 정의하고
구조체 내에 term 단어, docFreq 문서 빈도, postings 포스팅 리스트를 저장함
검색할 때 요소를 빠르게 찾기 위해서 메모리에 효율적으로 저장해야하고
그 방법으로는 해시 테이블과 트리가 있음
* hash table
각 단어를 고유한 정수로 변환하는 해싱을 통해 얻은 그 정수를 인덱스로 데이터를 저장
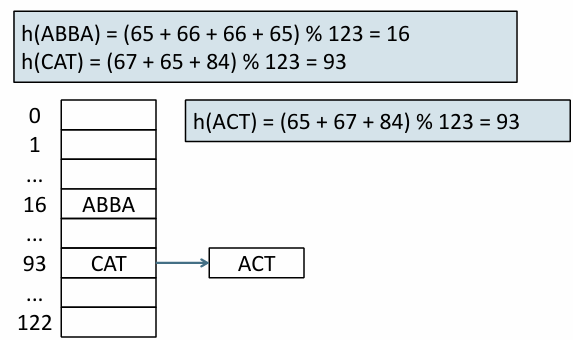
장점 - 트리보다 더 빠르게 검색 가능
단점
- 작은 차이 구분이 어려움 ...

judgement - judgment 같은 의미이지만 구성 철자의 차이로 전혀 다른 해시값을 가짐
= 접두어 검색이 불가능함
- 재해싱 필요함 = 단어 수가 늘어나서 해시 테이블을 확장하고 재해싱할 필요가 발생함
* binary tree
- 최대 자식을 두 개 가지는 트리
- 알파벳 순서에 따라 단어들이 트리에 배치 (예를 들어 A-M으로 시작하면 왼쪽, N-Z로 시작하면 오른쪽)
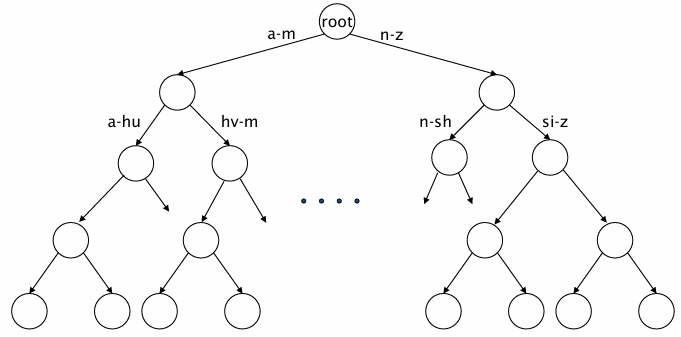
장점
- 철자 변형 처리가 쉬움 :: 유사한 단어는 인접하게 배치됨
- 접두어 검색 가능 :: automat*으로 검색하면 automatic, automation 등으로 쉽게 찾을 수 있음 (해당 지점부터 하위 노드를 확인하면 되기 때문)
단점
- 트리는 해시 테이블보다 검색 속도가 느림 O(log M)
- 균형있는 트리 형태여야 효율적인 검색 성능을 유지할 수 있음. 데이터 삽입이나 삭제 시 트리 재정렬 필요
* binary tree > balanced tree and skewed tree
balanced tree 균형 트리. 모든 노드가 균형있게 분포. 검색 성능 최적화
skewed tree 편향 트리. 노드가 한쪽으로 치우쳐있음. 검색 성능 나쁨
* binary tree > b-tree
- 각 내부 노드에 자식을 여러 개 가질 수 있도록 확장한 트리
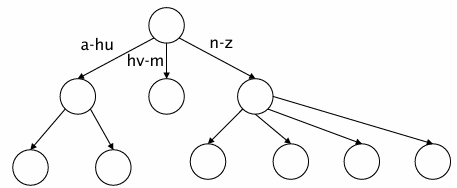
- 트리 높이를 줄여서 검색 속도를 향상시키고 균형을 유지하기 쉬워짐
- 트리를 큰 규모로 확장하면서도 균형을 유지해야할 때 b-tree를 사용하면 검색 효율이 높아짐
2. Wild-card Queries
* wildcard 역할
mon* 이라고 하면 mon으로 시작하는 모든 단어 출력 > 철자 변형 or 불확실한 or 다른 단어를 찾기 쉬움
* btree에서의 wildcard
* word*
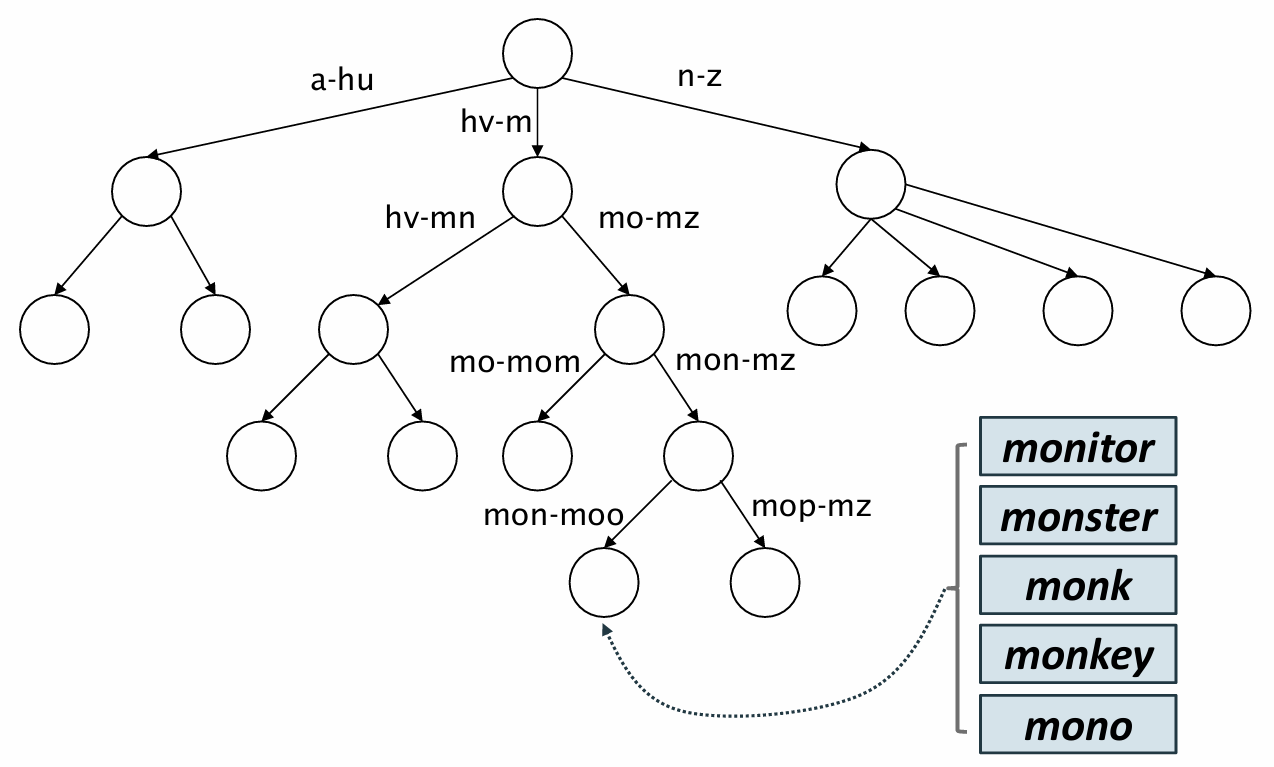
mon*을 이용해 mon으로 시작하는 단어는 해당 노드와 해당 노드 하위 노드에만 있음
b-tree의 특정 범위를 설정해서 검색할 수 있음
* *word
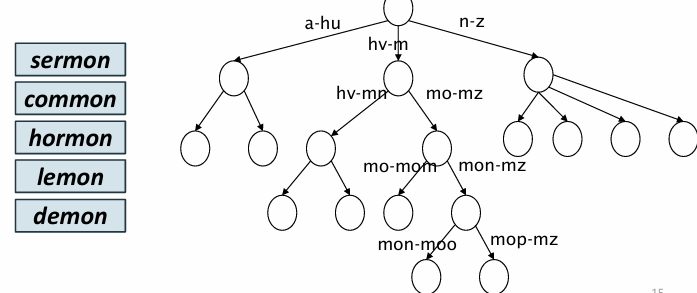
*mon을 이용해 mon 으로 끝나는 단어를 찾을 때 일반 b-tree로는 찾기 어려움
reverse b-tree를 이용해서 단어를 거꾸로 저장하고 뒤부터 검색함
lemon을 찾을 때는 reverse b-tree에서 nomel로 저장하고 mon으로 끝나는 단어들을 찾음
* wo*rd
pro*cent 처럼 와일드카드 문자가 단어의 중간에 포함되는 경우
pro와 cent로 나누어 각각의 트리에서 검색하고 교집합을 찾아야함
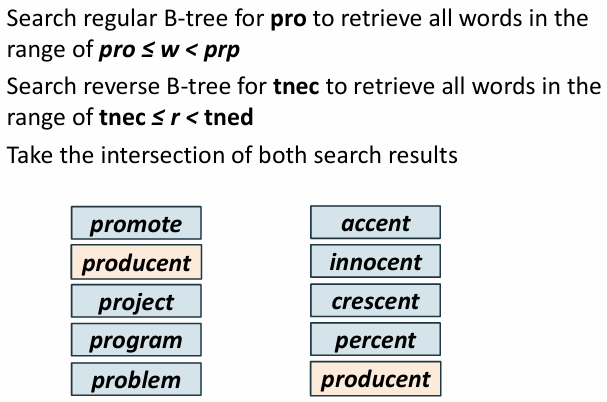
pro로 시작하는 단어들과 cent로 끝나는 단어들을 모으고
공통된 결과인 producent 출력
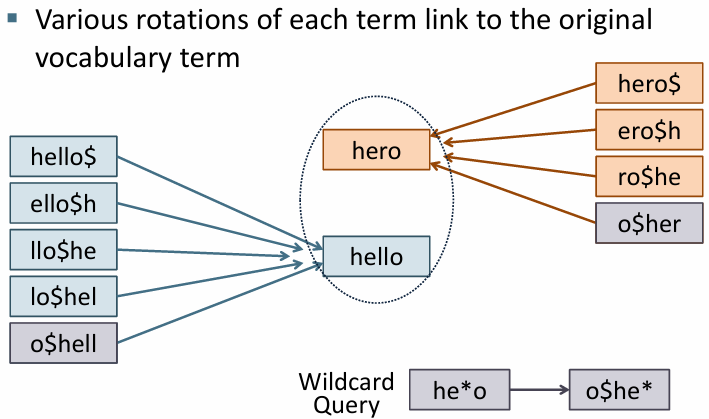
* permuterm index
- 각 단어를 여러 가지 형태로 회전시킨 후 와일드카드 쿼리를 효율적으로 처리
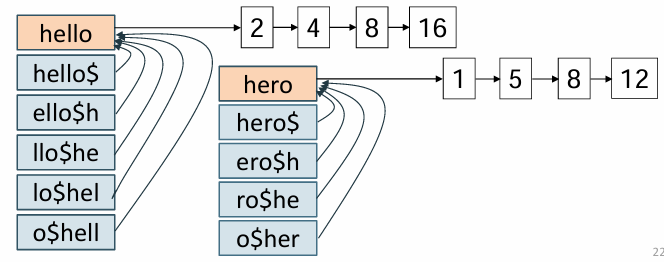
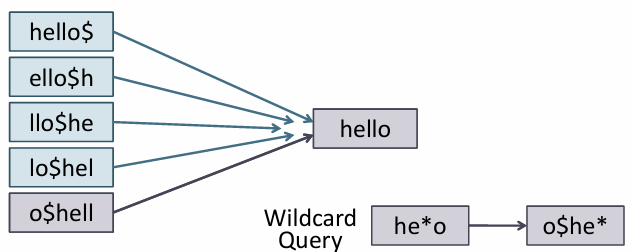
모든 회전 형태를 저장하기 때문에 인덱스가 커짐
permuterm 인덱스를 트리 구조로 저장할 수 있음
$ 기호는 단어 끝에 추가하고 회전을 완료하면
각 회전 형태는 적합한 b-tree 노드 위치에 저장
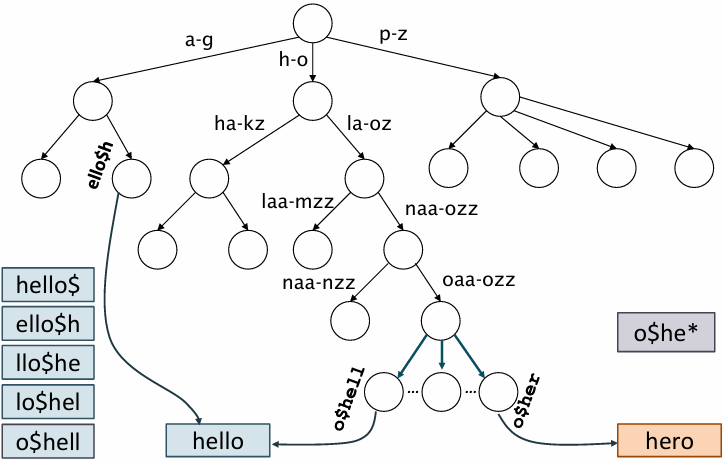
o$he*는 o$he로 시작하고 그 뒤는 어떤 형태든 가능하므로
시작하는 위치를 찾아서 이 위치를 포함하는 단어들을 검색함
> permuterm 인덱스를 사용하면 와일드카드가 단어의 시작, 중간, 끝에 위치할 때
회전 형태로 단어를 저장하니까 어디에 위치하든 모든 검색을 쉽게 처리할 수 있음
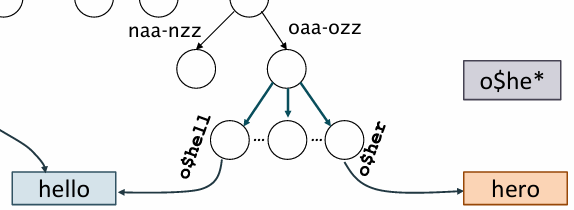
처음에 이 부분이 헷갈렸었는데
oaa - ozz 범위에 해당하는 o$hell ~ o$her 부분은
hello를 permuterm 인덱스를 사용해 회전한 결과물을 저장할 수 있는 위치이고
그 중에서 o$hell 를 회전하면 hello$를 결과로 출력할 수 있음
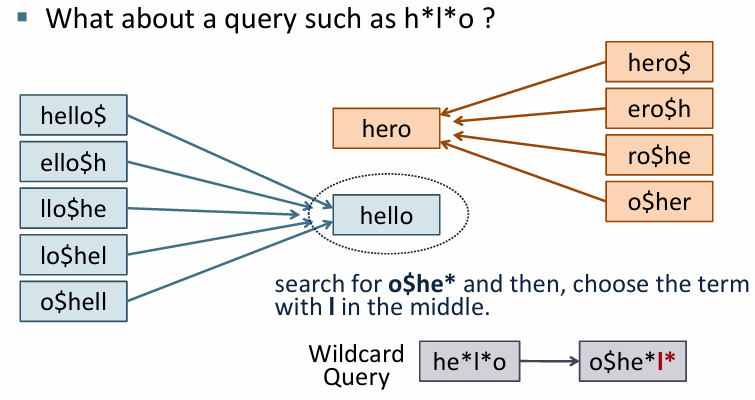
- h로 시작하고 l이 중간에 있고 o로 끝나는 단어
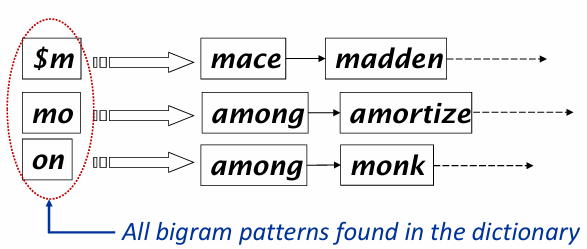
* k-gram index
- k개의 연속적인 문자를 기준으로 단어를 나누는 방식
castle에 3-그램을 적용하면 cas, ast, stl, tle 로 분할됨
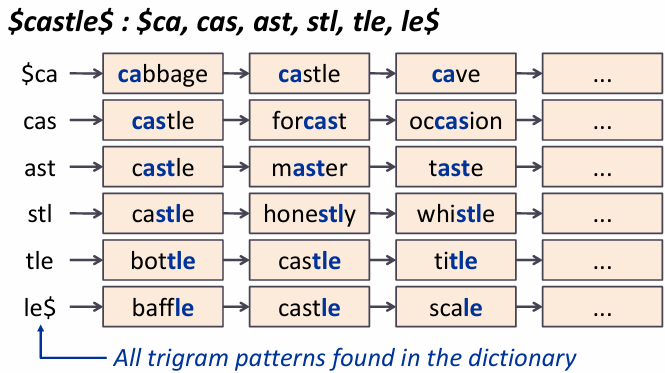
- k그램을 인덱스에 저장해서 특정 쿼리를 빠르게 처리할 수 있음
만약 mon에서의 2gram이면
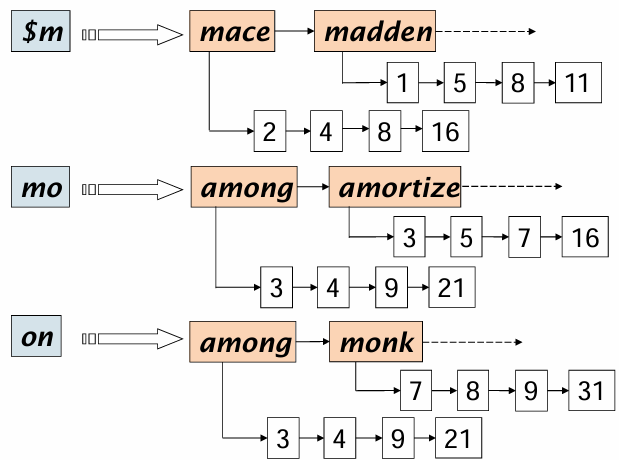
만약 re*ve쿼리를 3그램으로 분할하면
re와 ve를 기준으로 검색하고 그 결과를 and로 연산함
* k-gram index > post filtering
k그램 인덱스는 검색 범위를 좁히는 데 유용하지만
정확히 일치하지 않는 단어가 포함될 수 있어서
후처리 단계에서 검색 결과를 다시 한 번 검토하고
일치하지 않는 것은 필터링하는 것
만약 red*를 처리해야한다면
retired와 redeem은 포함될텐데 그 중 retired를 제거하고 redeem은 포함되도록 함
* k-gram index > problem
se*ate AND fil*er 같은 쿼리는 각 와일드카드 쿼리를 모두 찾아 교차 연산을 해야해서 연산이 많고 오래 걸림
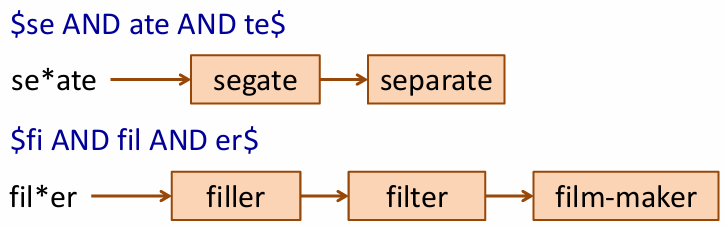
* processing wild card queries
기본적인 처리 비용이 높은 와일드 쿼리는 일반적인 검색 엔진의 처리 비용을 높이니까 고급 검색 기능으로 제공되어 특정 패턴을 검색할 때만 사용할 수 있도록 제한을 두어 엔진 부하를 줄일 수 있음
3. Spelling Correction
* spelling correction
- 인덱싱 전 문서에 있는 오타 교정
- 사용자 질의어에 포함된 쿼리 오타 교정
- 단일 단어 교정 : 개별적인 단어를 검사해서 오타 확인
- 문맥 민감 교정 : 주변 단어를 고려해서 교정
* document correction
- ocr로 인한 교정 필요 : 유사한 생김새의 단어들 오타
- 키보드 오류 교정 필요 : 쿼티 키보드에서 인접한 키들이 바뀌는 경우
* query correction
- 사전에 없는 쿼리 교정 필요 : 사전에 없는 단어가 포함되었다면 올바른 철자 제안
* isolated word correction
- 대체 단어 선택 : 잘못 입력된 단어 교정 , 대체 단어 중 가장 가까운(편집 거리 = 두 단어 간 차이를 계산해서 가장 가까운 단어 찾기, k-gram 중복 = 두 단어가 공유하는 k 그램 수 사용해서 유사성 판단) 단어 선택 (문서 출현 빈도, 사용자 쿼리 빈도 등)
* edit distance
- 두 문자열을 동일하게 만들기 위해 필요한 최소 편집 작업 수
- 삽입, 교체, 삭제
예제1. cat에서 dog로 바꿀 때

교체 3번
예제2. long 에서 short으로 바꿀 때
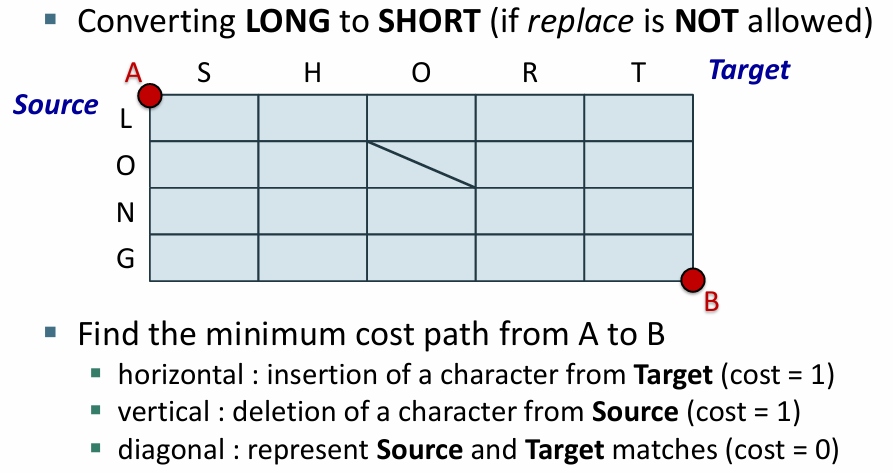
다르면 삭제하고 삽입해야함
삭제 4회 삽입 5회
예제3. long에서 short로 바꿀 때 대체 허용
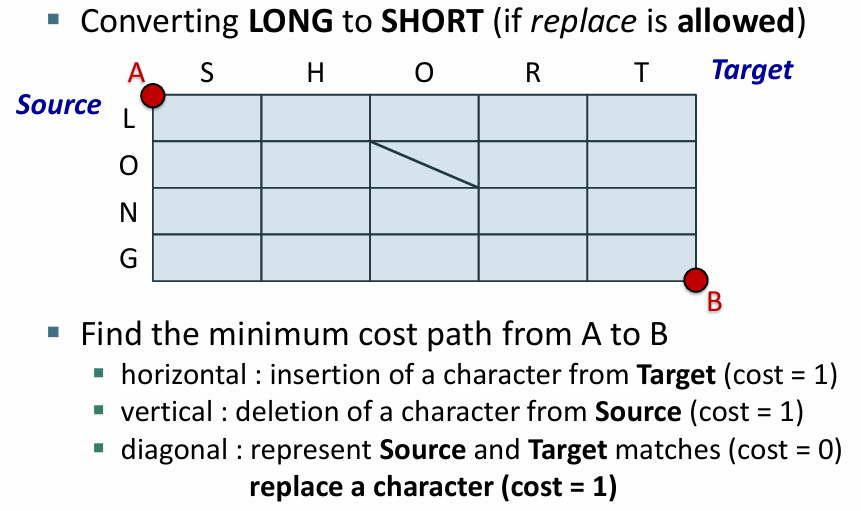
두 문자가 다른 경우 대체 연산 수행 가능
다르면 대체
대체 4회 삽입 1회
예제4. cats에서 fast로
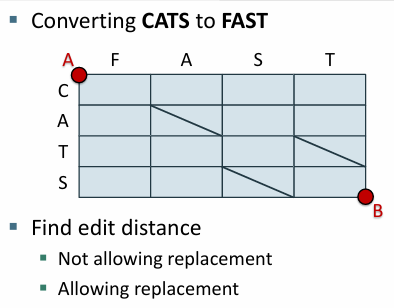
대체를 허용하지 않고
문자가 일치할 때만 대각선 이동
삭제 2회 삽입 3회
대각선 1회 (같으니까 카운트 안함)
예제5. cats에서 fast로 대체 허용
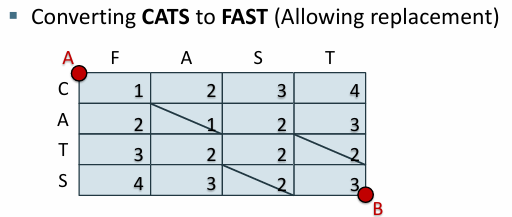
불일치하는 대각선에서는 대체하고 카운트 업
일치하면 대각선
대체 2회 삽입 1회
대각선 2회 (카운트 안 함)
* weighted edit distance
- 기본적인 편집 거리에서는 삽입과 삭제, 대체 동일한 비용을 가짐
- 가중치 편집 거리에서는 다른 가중치를 부여해서 정밀하게 교정
- ocr 오류나 키보드 오타가 자주 발생하는 경우에 대해 교정 비용을 적게 설정, 유사한 문자 간의 대체 비용을 줄임
* using edit distance
- 쿼리문의 단어가 잘못되었을 가능성이 있을 때
편집 거리가 특정 값 이하인 사전의 모든 단어를 나열해서 후보를 만들고
사용자에게 제안함
- 후보군을 모두 사용자에게 제시해서 선택하게 하는 것은 오래 걸림
- 가장 가능성이 높은 단어만 추천어로 제시하거나 사용해서 검색 (비용을 줄일 수 있음)
* edit distance to all dictionary terms
- 잘못 인풋된 단어에 대해 대체할 모든 후보군을 제시하는 것(모든 단어와 편집거리 비교 후 제시)은 비용 소모가 큼
- 대규모라면 더 부담
* k-gram overlap 활용
편집 거리 계산 범위를 줄일 수 있는 방법
문자열을 k로 잘라서 얻는 조각들과 잘못된 단어가 겹치는 사전 단어만 추려서 후보군을 줄임
단어 조각들을 비교하는 방식
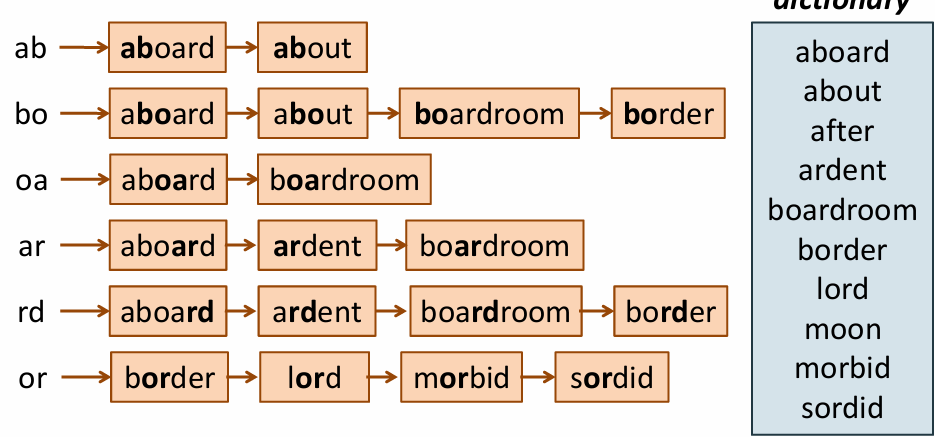
모든 사전 단어에서 가능한 k-gram을 모두 생성해서 k-gram인덱스를 만들어서
특정 k-gram을 포함하는 모든 단어에 빠르게 접근할 수 있게 함
ab라는 2gram이 포함되는 단어에는 aboard, about 이 있음
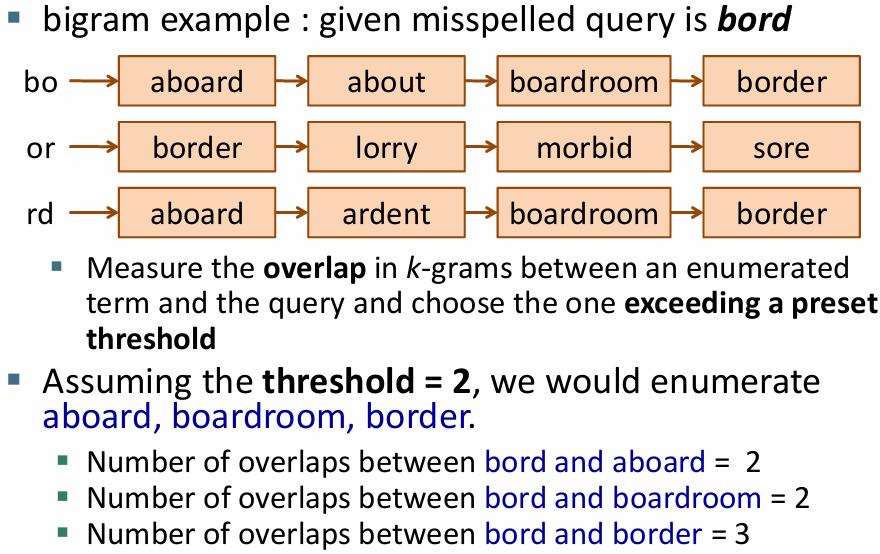
입력된 bord는 잘못된 단어라고 판단되었으니
bord의 k-gram을 만들고 k-gram 인덱스를 통해
입력된 bord의 k-gram과 중첩되는 부분을 가진 단어를 찾음
중첩된 k-gram이 2개 이상인 것만 선택하도록 임계값을 2로 정하면
aboard, boardroom, border로만 후보가 줄어들음

선택된 후보 단어들과 오타 단어의 편집 거리를 계산하고 가장 적은 비용으로 변환할 수 있는 단어를 선택함
> 편집 거리 계산 후 실제로 봤을 때 타당함이 적은 단어가 선택될 수 있어서 중첩 측정 방법 중 정규화된 중첩 측정 방법을 사용해서 k-gram 겹침 정도를 평가해야함
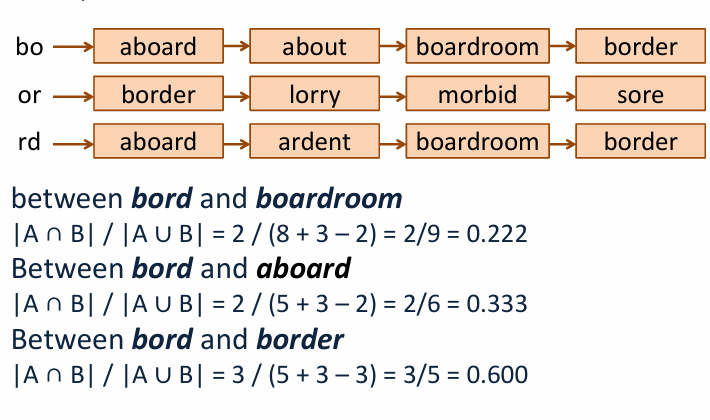
* k-gram overlap 정규화 > jaccard 계수를 이용하는
- Jaccard 계수 = 두 집합의 교집합을 합집합으로 나눈 값

- 1에 근접할수록 유사한 집합, 0에 가까울수록 차이가 큰 집합
- jaccard 계수가 특정 임계 값을 초과하는 후보 단어들만 편집 거리를 계산해서 후보로 제시
- 오타 단어와 후보 단어들의 jaccard 계수를 계산해서 가장 유사한 것 선택
* Context-sensitive spelling correction
- “flew form Heathrow” 라는 문장에서 form은 from의 오타일 가능성이 높음
- 단어만 보면 문제 없어 보여서 오타로 인식되지 않지만 문맥을 고려하면 수정해야함
- 주변의 단어를 함께 고려해서 사용자가 원했던 문장을 추천해줌
- 단어 조합과 의미 기반의 문맥 파악이 필수적
- 단어 후보 생성 : 사전 근처에 있는 것으로 후보
- 모든 조합 검사 : 모든 조합 중 가장 유의미한 것을 찾기에는 비용이 많이 드니까 휴리스틱 적용.
특히 히트 기반 철자 교정으로 검색 결과가 많은 대체어를 우선적으로 제안해보는.
쿼리 로그 분석으로 자주 검색 or 인기있는 단어로 제안
- 계산 비용 문제 : 문맥 기반 철자 교정은 모든 쿼리에 적용하기에 비효율적, 결과가 적은 쿼리(적은 문서와 일치하는 쿼리)에 대해서만 적용함. = 실제 사용자에게 도움줄 가능성이 높은 쿼리에만 집중.

'[ Computer Science ] > Information Retrieval' 카테고리의 다른 글
| [Information Retrieval] 정보 검색 6. Scoring, Term Weighting, and the Vector Space Model (6) | 2024.10.31 |
|---|---|
| [Information Retrieval] 정보 검색 5. Index compression (3) | 2024.10.31 |
| [Information Retrieval] 정보 검색 4. Index construction (1) | 2024.10.30 |
| [Information Retrieval] 정보 검색 2. The term vocabulary and postings lists (5) | 2024.10.27 |
| [Information Retrieval] 정보 검색 1. Boolean Retrieval (3) | 2024.10.27 |